Jonny Langefeld
Software Engineer

All views expressed are my own and not affiliated with current or former employers.
Introducing kubectl mc
If you work at a company or organization that maintains multiple Kubernetes clusters it is fairly common to connect to multiple different kubernetes clusters throughout your day. And sometimes you want to execute a command against multiple clusters at once. For instance to get the status of a deployment across all staging clusters. You could run your kubectl command in a bash loop. That does not only require some bash logic, but also it’ll take a while to get your results because every loop iteration is an individual API round trip executed successively.
kubectl mc (short for multi cluster) supports this workflow and significantly reduces the return time by executing the necessary API requests in parallel go routines.
It’s doing that by creating a wait group channel with n max entries.
The max amount of entries can be configured with the -p flag. It then iterates through a list of contexts that matched
a regex, given with the -r flag, and executes the given kubectl command in parallel go routines.
Installation
While you can install the binary via go get github.com/jonnylangefeld/kubectl-mc, it is recommended to use the krew
package manager. Check out their website for installation.
Run krew install mc to install mc.
In both cases a binary named kubectl-mc is made available on your path. kubectl automatically identifies binaries
named kubectl-* and makes them available as kubectl plugin. So you can use it via kubectl mc.
Usage
Run kubectl mc for help and examples. Here is one to begin with:
$ kubectl mc --regex kind -- get pods -n kube-system
kind-kind
---------
NAME READY STATUS RESTARTS AGE
coredns-f9fd979d6-q7gnm 1/1 Running 0 99m
coredns-f9fd979d6-zd4jn 1/1 Running 0 99m
etcd-kind-control-plane 1/1 Running 0 99m
kindnet-8qd8p 1/1 Running 0 99m
kube-apiserver-kind-control-plane 1/1 Running 0 99m
kube-controller-manager-kind-control-plane 1/1 Running 0 99m
kube-proxy-nb55k 1/1 Running 0 99m
kube-scheduler-kind-control-plane 1/1 Running 0 99m
kind-another-kind-cluster
-------------------------
NAME READY STATUS RESTARTS AGE
coredns-f9fd979d6-l2xdb 1/1 Running 0 91s
coredns-f9fd979d6-m99fx 1/1 Running 0 91s
etcd-another-kind-cluster-control-plane 1/1 Running 0 92s
kindnet-jlrqg 1/1 Running 0 91s
kube-apiserver-another-kind-cluster-control-plane 1/1 Running 0 92s
kube-controller-manager-another-kind-cluster-control-plane 1/1 Running 0 92s
kube-proxy-kq2tr 1/1 Running 0 91s
kube-scheduler-another-kind-cluster-control-plane 1/1 Running 0 92s
As you can see, each context that matched the regex kind executes the kubectl command indicated through the --
surrounded by spaces.
Apart from the plain standard kubectl output, you can also have everything in json or yaml output using the
--output flag. Here is an example of json output piped into jq to run a query which prints the context and the pod
name for each pod:
$ kubectl mc --regex kind --output json -- get pods -n kube-system | jq 'keys[] as $k | "\($k) \(.[$k] | .items[].metadata.name)" '
"kind-another-kind-cluster coredns-66bff467f8-6xp9m"
"kind-another-kind-cluster coredns-66bff467f8-7z842"
"kind-another-kind-cluster etcd-another-kind-cluster-control-plane"
"kind-another-kind-cluster kindnet-k4vnm"
"kind-another-kind-cluster kube-apiserver-another-kind-cluster-control-plane"
"kind-another-kind-cluster kube-controller-manager-another-kind-cluster-control-plane"
"kind-another-kind-cluster kube-proxy-dllm6"
"kind-another-kind-cluster kube-scheduler-another-kind-cluster-control-plane"
"kind-kind coredns-66bff467f8-4lnsg"
"kind-kind coredns-66bff467f8-czsf6"
"kind-kind etcd-kind-control-plane"
"kind-kind kindnet-j682f"
"kind-kind kube-apiserver-kind-control-plane"
"kind-kind kube-controller-manager-kind-control-plane"
"kind-kind kube-proxy-trbmh"
"kind-kind kube-scheduler-kind-control-plane"
Check out the github repo for a speed comparison. If you have any questions or feedback email me [email protected] or tweet me @jonnylangefeld.
Tags: kubernetes, addon, krew, multi cluster, cli, tool, go
Kubernetes: How to View Swagger UI
Often times, especially during development of software that talks to the kubernetes API server, I actually find myself looking for a detailed kubernetes API specification. And no, I am not talking about the official kubernetes API reference which mainly reveals core object models. I am also interested in the specific API paths, the possible headers, query parameters and responses.
Typically you find all this information in an openapi specification doc which you can view via the Swagger UI, ReDoc or other tools of that kind.
So the next logical step is to google for something like ‘kubernetes swagger’ or ‘kubernetes openapi spec’ and you’d hope for a Swagger UI to pop up and answer all your questions. But while some of those search results can lead you in the right direction, you won’t be pleased with the Swagger UI you were looking for.
The reason for that is the spec for every kubernetes API server is actually different due to custom resource definitions and therefore exposes different paths and models.
And that requires the kubernetes API server to actually generate it’s very own openapi specification, which we will do in the following:
First make sure that you are connected to your kubernetes API server as your current kube context. You can double check via kubectl config current-context. You then want to open a reverse proxy to your kubernetes API server:
kubectl proxy --port=8080
That saves us a bunch of authentication configuration that’s now all handled by kubectl. Run the following commands in a new terminal window to keep the reverse proxy alive (or run the reverse proxy in the background). Save the Swagger file for your kubernetes API server via the following command:
curl localhost:8080/openapi/v2 > k8s-swagger.json
As last step we now just need to start a Swagger ui server with the generated Swagger json as input. We will use a docker container for that:
docker run \
--rm \
-p 80:8080 \
-e SWAGGER_JSON=/k8s-swagger.json \
-v $(pwd)/k8s-swagger.json:/k8s-swagger.json \
swaggerapi/swagger-ui
Now visit http://localhost and you’ll get a Swagger UI including the models and paths of all custom resources installed on your cluster!

Tags: kubernetes, swagger, api, tips & tricks
How to write a Go API: The Ultimate Guide

“TIL” (today I learned) is an acronym I recently discovered (Example usage: “TIL what TIL means”). Since I’m ESL (English as Second Language) I use the urban dictionary a lot to look up these acronyms. “TIL” turned out to be a very useful term, because it’s true: One never stops learning. And so it happened that I started this blog writing about a Python Flask API and continued with a three part series on how to write a go API. And while there is a lot of valuable information in those posts, today I am writing about what I learned since then and what my current set of best practices is to write an efficient and production ready API.
Reading many blogs myself, I sometimes miss context on given examples. So I published a sample repo which can be found on github. Every code example in this post links to the source lines of this repo.
The following paragraphs feature a large set of best practices and why I like them. Send me an email or tweet me @jonnylangefeld if you feel like something is missing!
Table of Contents
- 1. Project Scaffolding
- 2. The tools.go Pattern
- 3. Command Line Flags With pflag
- 4. Structured Logging With zap
- 5. Graceful Exits
- 6. Log Version on Startup
- 7. Define Types in Their Own Package
- 8. chi as HTTP Framework
- 9. Custom Middlewares
- 10. Pagination
- 11. Database Integration With gorm
- 12. Database Integration Tests With dockertest
- 13. API Integration Tests With gomock
- 14. Render Responses With go-chi/render
- 15. Documentation as Code With http-swagger
- 16. Staged Dockerfile
1. Project Scaffolding
I use the following tree as project layout. More packages can be added under pkg.
├── Dockerfile
├── Makefile
├── docs # automatically generated by `make docs`
├── go.mod
├── go.sum
├── main.go # main.go in the root rather than in `/cmd` directory
├── pkg
│ ├── api # containing all API related functions and the router
│ │ ├── api.go
│ │ ├── api_test.go
│ │ └── operations.go
│ ├── db # all database interactions happen in here
│ │ ├── db.go
│ │ └── db_test.go
│ ├── middelware # for custom middlewares
│ │ ├── context.go
│ │ └── logger.go
│ └── types # our types get a separate package
│ └── types.go
├── readme.md
└── tools.go # tools.go to manage tool versions via go.mod
With that out of the way, lets look into the main.go file.
2. The tools.go Pattern
I’m really a fan of managing tool dependencies also through go modules. That pins their versions and includes them in my vendor directory. Marco Franssen wrote in-depth about this pattern in this blog post.
3. Command Line Flags With pflag
There are many ways to work with command line flags and configurations in go. One can go fancy with viper or stay simple with go’s built in flags package. I like pflag because of it’s simplicity and similarity to go’s own package, yet it offers POSIX/GNU-style flags making it more natural to use on your command line. The sample repo contains an example usage:
func init() {
pflag.StringVarP(&addr, "address", "a", ":8080", "the address for the api to listen on. Host and port separated by ':'")
pflag.Parse()
}
(source)
Pflag comes with help built in:
$ go-api -h
Usage of go-api:
-a, --address string the address for the api to listen on. Host and port separated by ':' (default ":8080")
4. Structured Logging With zap
This is certainly an opinionated decision, but my favorite logger is zap. It can be configured in all kinds of ways, but I like to keep it very simple. This is the configuration I use:
// configure logger
log, _ := zap.NewProduction(zap.WithCaller(false))
defer func() {
_ = log.Sync()
}()
(source)
Which gives me a beautiful log output like the following:
{"level":"info","ts":1601686510.597971,"msg":"starting up API...","version":"v1.0.0"}
{"level":"info","ts":1601686510.70517,"msg":"ready to serve requests on :8080"}
{"level":"info","ts":1601686516.446462,"msg":"served request","proto":"HTTP/1.1","method":"GET","path":"/articles","lat":0.002087763,"status":200,"size":13,"reqId":"C02C864PLVDL/gESGYmlmCu-000001"}
{"level":"info","ts":1601686521.3242629,"msg":"served request","proto":"HTTP/1.1","method":"GET","path":"/orders","lat":0.002300746,"status":200,"size":13,"reqId":"C02C864PLVDL/gESGYmlmCu-000002"}
{"level":"info","ts":1601686525.5588071,"msg":"gracefully shutting down"}
5. Graceful Exits
This one is not ultimately necessary but I’ve seen it a lot and ensures cleanup tasks when the API is shutting down. A graceful exit is implemented by making a channel in the beginning of your program and listening for a certain event, like this one for a keyboard interrupt:
// gracefully exit on keyboard interrupt
c := make(chan os.Signal, 1)
signal.Notify(c, os.Interrupt, syscall.SIGTERM)
(source)
At the end of the program, after starting the webserver in a go routine (see #5), we react to the signal:
<-c
log.Info("gracefully shutting down")
os.Exit(0)
(source)
6. Log Version on Startup
This one is also minor, but it turns out to be very useful to see the version by just reading the logs for debugging. It makes it clear which exact code base ran the code and resulted in a potential error.
The version is injected by using an unset version variable in the main.go file and setting it via the build command (for instance in your Makefile):
VERSION ?= $(shell git describe --match 'v[0-9]*' --tags --always)
build:
@go build -ldflags "-X main.version=$(VERSION)"
(source)
In the main.go file you can use the version as follows (after instantiating it via var version string):
// print current version
log.Info("starting up API...", zap.String("version", version))
(source)
7. Define Types in Their Own Package
Types should be reusable. Let’s say someone was to build a command line interface interacting with your API, they would appreciate if they could just import your API types. So we define types as structs in pkg/types/types.go (we will get to the struct tags and the doc strings later):
// Article is one instance of an article
type Article struct {
// The unique id of this item
ID int `gorm:"type:SERIAL;PRIMARY_KEY" json:"id" example:"1"`
// The name of this item
Name string `gorm:"type:varchar;NOT NULL" json:"name" example:"Skittles"`
// The price of this item
Price float64 `gorm:"type:decimal;NOT NULL" json:"price" example:"1.99"`
} // @name Article
(source)
8. chi as HTTP Framework
My http framework of choice these days is go-chi/chi (upon recommendation by @elsesiy - thank you!) for its light weight, idiomatic implementation, but mainly for its 100% compatibility with net/http allowing you to use any existing middleware.
The server is started as go routine and listens on the configured address:
// start the api server
r := api.GetRouter(log, dbClient)
go func() {
if err := http.ListenAndServe(addr, r); err != nil {
log.Error("failed to start server", zap.Error(err))
os.Exit(1)
}
}()
(source)
The router gets configured in the api package, setting the db client and the logger:
func GetRouter(log *zap.Logger, dbClient db.ClientInterface) *chi.Mux {
r := chi.NewRouter()
r.Use(middleware.RequestID)
SetDBClient(dbClient)
if log != nil {
r.Use(m.SetLogger(log))
}
buildTree(r)
return r
}
(source)
The tree of requests looks in code just as it would like in a folder structure. Every sub request is attached to its parent. Here is an example request tree, that handles articles and orders for a store:
func buildTree(r *chi.Mux) {
r.HandleFunc("/swagger", func(w http.ResponseWriter, r *http.Request) {
http.Redirect(w, r, r.RequestURI+"/", http.StatusMovedPermanently)
})
r.Get("/swagger*", httpSwagger.Handler())
r.Route("/articles", func(r chi.Router) {
r.With(m.Pagination).Get("/", ListArticles)
r.Route("/{id}", func(r chi.Router) {
r.Use(m.Article)
r.Get("/", GetArticle)
})
r.Put("/", PutArticle)
})
r.Route("/orders", func(r chi.Router) {
r.With(m.Pagination).Get("/", ListOrders)
r.Route("/{id}", func(r chi.Router) {
r.Use(m.Order)
r.Get("/", GetOrder)
})
r.Put("/", PutOrder)
})
}
(source)
9. Custom Middlewares
In the tree above, you can spot the usage of
r.Route("/{id}", func(r chi.Router) {
r.Use(m.Article)
r.Get("/", GetArticle)
})
(source)
Custom middlewares live in the middleware package. m is our custom middleware, imported through
m "github.com/jonnylangefeld/go-api/pkg/middelware"
(source)
Custom middlewares are very powerful. They are basically an injection into the sequence of handlers of the api and can do anything ‘along the way’. In this instance we know we are in a part of our router tree, that will always require the article object pulled from the database. So we inject a custom middleware, that does exactly that for us and injects it into the context of the request. The context is available through the entire handler chain, so for any succeeding handler our object will be available.
The following middelware is the http.Handler we used above via r.Use(m.Article) and injects the article object into the context.
// Article middleware is used to load an Article object from
// the URL parameters passed through as the request. In case
// the Article could not be found, we stop here and return a 404.
func Article(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
var article *types.Article
if id := chi.URLParam(r, "id"); id != "" {
intID, err := strconv.Atoi(id)
if err != nil {
_ = render.Render(w, r, types.ErrInvalidRequest(err))
return
}
article = DBClient.GetArticleByID(intID)
} else {
_ = render.Render(w, r, types.ErrNotFound())
return
}
if article == nil {
_ = render.Render(w, r, types.ErrNotFound())
return
}
ctx := context.WithValue(r.Context(), ArticleCtxKey, article)
next.ServeHTTP(w, r.WithContext(ctx))
})
}
(source)
Later on in our handlers, we just pull the article from the context, without reaching out to the database again.
func GetArticle(w http.ResponseWriter, r *http.Request) {
article := r.Context().Value(m.ArticleCtxKey).(*types.Article)
if err := render.Render(w, r, article); err != nil {
_ = render.Render(w, r, types.ErrRender(err))
return
}
}
(source)
The article object is available for every child in the request tree, which makes these custom middlewares so powerful.
10. Pagination
Click here to read the separate blog post on pagination.
11. Database Integration With gorm
In previous blog posts I have described how I use gorm as an object relational mapping framework in go APIs. That has not changed so far. I like the ease of use and the ability to still write raw SQL if I need to. That especially comes in handy if the underlying database is postgres, which has a bunch of custom features that no ORM would naturally cover. Go check out my old blog post for in-depth coverage.
However, I did change how I interact with the database client. Rather than just using the bare-bone gorm.Open() call in the main() function, I do write a custom client interface, that wraps the gorm client. The custom client interface features a Connect() function to establish the database and a bunch of functions that will be called by the different API endpoints. This interfacing will help us later to write API integration tests with integration tests with gomock.
// ClientInterface resembles a db interface to interact with an underlying db
type ClientInterface interface {
Ping() error
Connect(connectionString string) error
GetArticleByID(id int) *types.Article
SetArticle(article *types.Article) error
GetArticles(pageID int) *types.ArticleList
GetOrderByID(id int) *types.Order
SetOrder(order *types.Order) error
GetOrders(pageID int) *types.OrderList
}
// Client is a custom db client
type Client struct {
Client *gorm.DB
}
(source)
This pattern allows us to still access the underlying client if we ever needed to. Now this does create a funny looking construct that looks like client.Client, but I’ve seen this pattern elsewhere and actually think it is quite useful, to still make lower level function calls available to higher level interfaces.
12. Database Integration Tests With dockertest
Database integration tests are important to be done on a database as close as possible to the one intended to be used in production. That is because databases have many different flavors and they all have their own quirks. Especially for a database like postgres this is important, as postgres offers a lot of custom functions and features, that can’t be replicated through other testing methods like dependency injection.
The best way to create a short-lived database, that’s just there during testing and always has the same state, is through a docker container. That can be easily run locally and on CI systems and ensures that we interact correctly with the actual database.
Just as the last topic, I have describe this concept in a blog post last year and this has probably changed the least since I’ve blogged about it, so the old post is still accurate. To see how it integrates into the sample repository, check the pkg/db/db_test.go file.
13. API Integration Tests With gomock
gomock is a great tool for any kind of integration tests. The basic idea is to mock an interface of another package, so you don’t have to set up a dependency just for testing. Imagine a tool that pulls in data from the Google Calendar API, you don’t want to be dependent on the Google Calendar API up and running during your integration tests. So you mock the dependency. The assumption here is that the used dependency is itself tested properly. The way this is done is through an interface, for which we can replace functions during our tests.
In the scenario of our demo go-api, our API operations depend on the database. That would mean that we need an up and running database for API integration tests. However, we covered proper database integration tests earlier, so now we can assume those database calls are working properly. And to not also depend on the up and running database during API integration tests, we mock the database calls as follows:
First off, add gomock to the tools.go file. Then we’ll add this section to the api integration tests:
//go:generate $GOPATH/bin/mockgen -destination=./mocks/db.go -package=mocks github.com/jonnylangefeld/go-api/pkg/db ClientInterface
func getDBClientMock(t *testing.T) *mocks.MockClientInterface {
ctrl := gomock.NewController(t)
dbClient := mocks.NewMockClientInterface(ctrl)
dbClient.EXPECT().GetArticles(gomock.Eq(0)).Return(&types.ArticleList{
Items: []*types.Article{
&testArticle1,
&testArticle2,
},
})
dbClient.EXPECT().GetArticles(gomock.Eq(1)).Return(&types.ArticleList{
Items: []*types.Article{
&testArticle2,
},
})
dbClient.EXPECT().GetArticleByID(gomock.Eq(1)).Return(&testArticle1).AnyTimes()
dbClient.EXPECT().SetArticle(gomock.Any()).DoAndReturn(func(article *types.Article) error {
if article.ID == 0 {
article.ID = 1
}
return nil
}).AnyTimes()
return dbClient
}
(source)
The first line of this section is important, even though commented out. It tells go generate (which we will call through a Makefile target) that here is an execution to be done. It means that mockgen should mock the ClientInterface in the github.com/jonnylangefeld/go-api/pkg/db package. It does that by creating a new file (./mocks/db.go in this case) with a whole bunch of generated code that is not meant to be touched. But we can now use the mock interface in the form of mocks.NewMockClientInterface(ctrl). All functions of the mocked interface are available in this mock and can now be overwritten with custom logic. In the example above we are responding with different returns for different IDs of the GetArticles() function and mock some other functions of the interface as well.
Now once we run the actual API integration tests, we don’t initialize the API router with an interface to the actual database, but with the just created mock interface. That way the actual database is never called.
r := GetRouter(nil, getDBClientMock(t))
(source)
The rest of the API integration tests is less magical and we just use a helper function to send an http request against an in-memory http server.
body := bytes.NewReader([]byte(test.body))
gotResponse, gotBody := testRequest(t, ts, test.method, test.path, body, test.header)
assert.Equal(t, test.wantCode, gotResponse.StatusCode)
if test.wantBody != "" {
assert.Equal(t, test.wantBody, gotBody, "body did not match")
}
(source)
Every test request gets routed to its corresponding API endpoint, which internally calls the functions on the database interface, that we just mocked above.
14. Render Responses With go-chi/render
go-chi comes with a built-in way to render and bind data for your json API. This simplifies our responses to something simple as render.Render(w, r, article) and go-chi/render will take care of the rest and that it reaches the client in the right format.
func GetArticle(w http.ResponseWriter, r *http.Request) {
article := r.Context().Value(m.ArticleCtxKey).(*types.Article)
if err := render.Render(w, r, article); err != nil {
_ = render.Render(w, r, types.ErrRender(err))
return
}
}
(source)
What’s happening behind the scenes here is that the article object implements the go-chi/render.Renderer and go-chi/render.Binder interfaces.
// Render implements the github.com/go-chi/render.Renderer interface
func (a *Article) Render(w http.ResponseWriter, r *http.Request) error {
return nil
}
// Bind implements the the github.com/go-chi/render.Binder interface
func (a *Article) Bind(r *http.Request) error {
return nil
}
(source)
Once these two functions are implemented, you are ready to go and the article object can be rendered in responses and bound in POST or PUT requests.
15. Documentation as Code With http-swagger
The openapi V3 specification is the industry standard and a great way to document your API for your users. However, you don’t want to end up writing an independent yaml or json file, that you have to update anytime you change something in your API.
On top of that it would be great if other developers working on the code have the same documentation of a given API function available. http-swagger comes in to fix these problems. The source-of-truth of your API documentation will remain in the docstrings of your handlers, but will be automatically rendered into an openapi spec and displayed via the swagger-ui. Let’s look into how it works.
You might have seen docstrings that look similar to this
// GetArticle renders the article from the context
// @Summary Get article by id
// @Description GetArticle returns a single article by id
// @Tags Articles
// @Produce json
// @Param id path string true "article id"
// @Router /articles/{id} [get]
// @Success 200 {object} types.Article
// @Failure 400 {object} types.ErrResponse
// @Failure 404 {object} types.ErrResponse
func GetArticle(w http.ResponseWriter, r *http.Request) {
(source)
These are a whole bunch of key words, interpreted by swaggo. Check the full documentation here. We are basically collecting all human readable text of the documentation here in the docstring of that handler function and also make links to the possible returned objects. If we change something here, we’ll just have to run make generate-docs, and we’ll get all files in the docs directory, which includes an openapi json, yaml and some go code, automatically generated. If we want to inject something into the spec, like the current build version, we can do so from the main file:
docs.SwaggerInfo.Version = version
(source)
All that’s left to do now is expose the swagger UI via an endpoint:
r.HandleFunc("/swagger", func(w http.ResponseWriter, r *http.Request) {
http.Redirect(w, r, r.RequestURI+"/", http.StatusMovedPermanently)
})
r.Get("/swagger*", httpSwagger.Handler())
(source)
Now once that’s all set up, we can access the swagger UI via http://localhost:8080/swagger, and we get the fully featured swagger UI for our API:
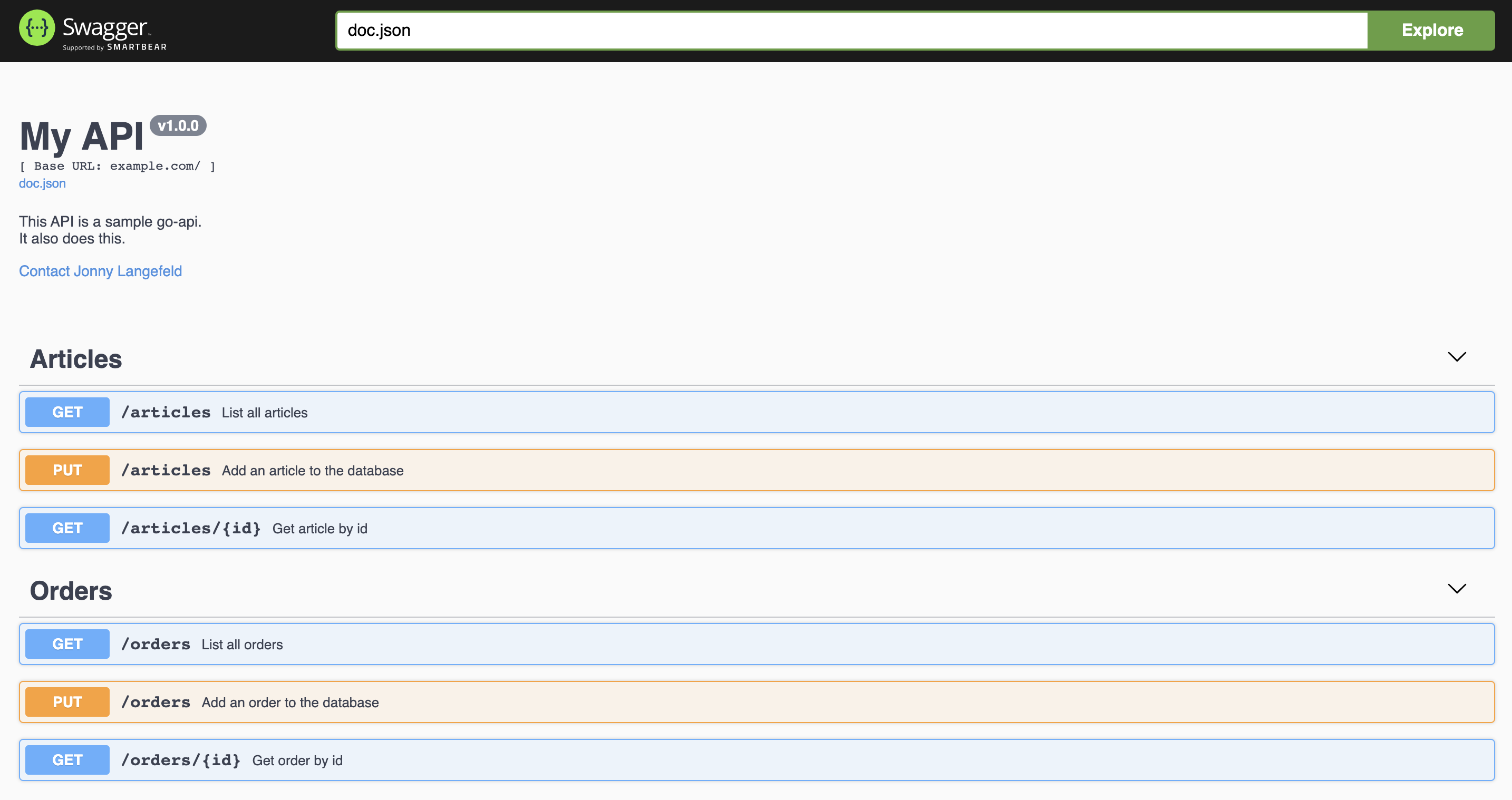
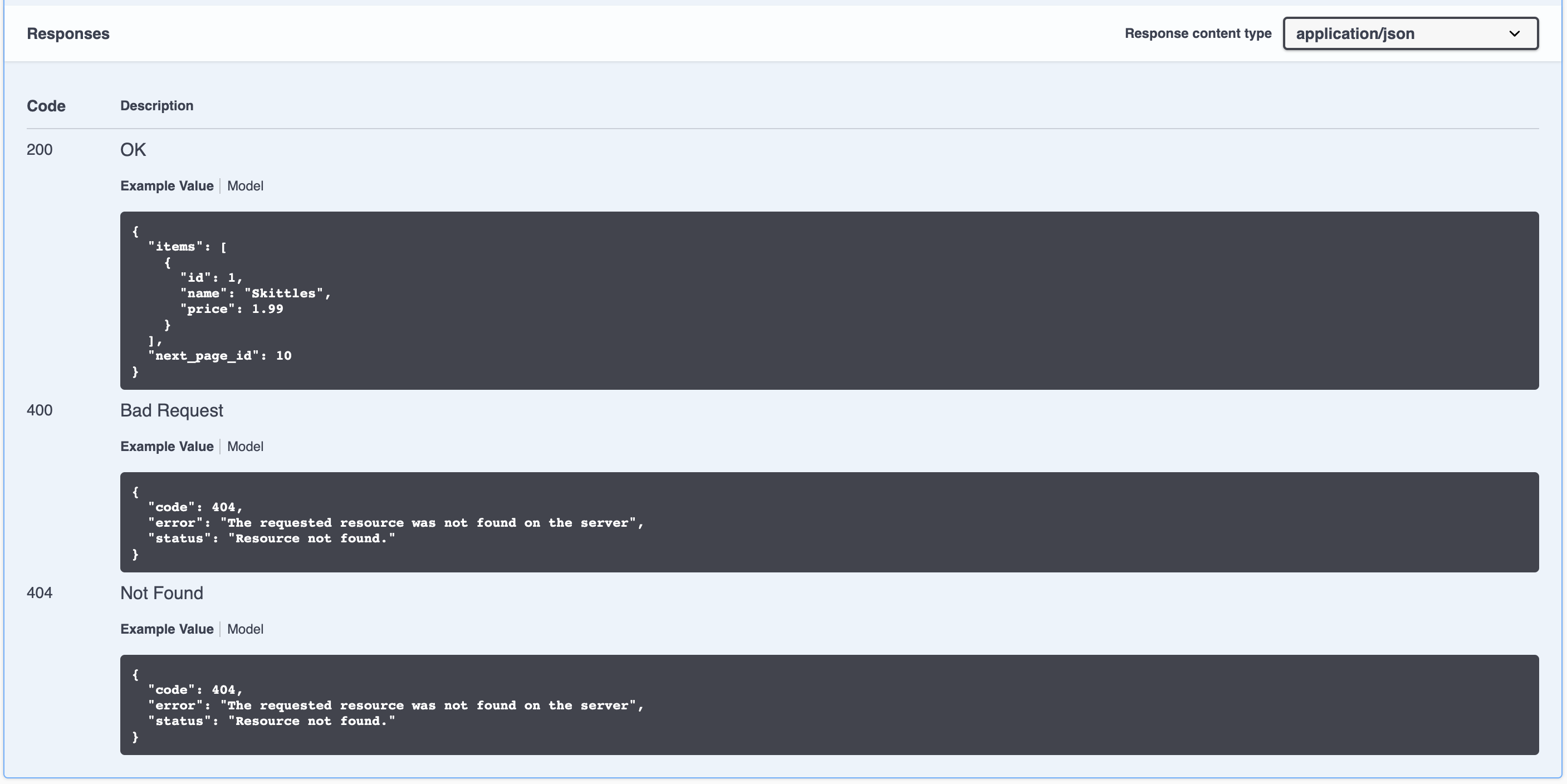
It comes with all the models and even examples that you can add via struct tags like the following:
// Article is one instance of an article
type Article struct {
// The unique id of this item
ID int `gorm:"type:SERIAL;PRIMARY_KEY" json:"id" example:"1"`
// The name of this item
Name string `gorm:"type:varchar;NOT NULL" json:"name" example:"Skittles"`
// The price of this item
Price float64 `gorm:"type:decimal;NOT NULL" json:"price" example:"1.99"`
} // @name Article
(source)
16. Staged Dockerfile
Last but not least, I always recommend to have a staged Dockerfile to allow us to use a distroless executable-stage image. That means your build stage is separated from the actual executable stage and will make your posted image way smaller.
Restricting what’s in your runtime container to precisely what’s necessary for your app is a best practice employed by Google and other tech giants that have used containers in production for many years. It improves the signal to noise of scanners (e.g. CVE) and reduces the burden of establishing provenance to just what you need.
(source)
That means that we build our binary through a docker container via the following:
FROM golang:1.14 as gobuild
ARG VERSION=latest
WORKDIR /go/src/github.com/jonnylangefeld/go-api
ADD go.mod go.sum main.go ./
ADD vendor ./vendor
ADD pkg ./pkg
ADD docs ./docs
RUN CGO_ENABLED=0 GOOS=linux GO111MODULE=on go build -mod=vendor -o go-api -ldflags "-X main.version=$VERSION" main.go
(source)
And then we just copy that binary over to a distroless docker image:
FROM gcr.io/distroless/base
COPY --from=gobuild /go/src/github.com/jonnylangefeld/go-api/go-api /bin
ENTRYPOINT ["/bin/go-api"]
(source)
Tags: go, golang, api, programming, software development, repo, ultimate guide, dockertest, chi, swagger, structured logging, best practices, how to
How to write a Go API: Pagination
This plog post is part of a series of blog posts on how to write a go API with all best practices. If you’re here just for pagination, keep on reading. If you want all the context including project setup and scaffolding, read the Ultimate Guide.
Pagination is important for any possible list response of arrays with undefined length. That is so we control the throughput and load on our API. We don’t want to query the database for 10 Million items at once and send them all through the http server. But rather we send a finite subset slice of the array of undefined length.
The general concept will be an API object with an Items slice and a NextPageID:
// ArticleList contains a list of articles
type ArticleList struct {
// A list of articles
Items []*Article `json:"items"`
// The id to query the next page
NextPageID int `json:"next_page_id,omitempty" example:"10"`
} // @name ArticleList
(source)
To retrieve the next page ID via the URL, we’ll use a custom middleware:
r.With(m.Pagination).Get("/", ListArticles)
(source)
The With() call injects a middleware for just the current sub-tree of the router and can be used for every list response. Let’s have a closer look into the Pagination middleware:
// Pagination middleware is used to extract the next page id from the url query
func Pagination(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
PageID := r.URL.Query().Get(string(PageIDKey))
intPageID := 0
var err error
if PageID != "" {
intPageID, err = strconv.Atoi(PageID)
if err != nil {
_ = render.Render(w, r, types.ErrInvalidRequest(fmt.Errorf("couldn't read %s: %w", PageIDKey, err)))
return
}
}
ctx := context.WithValue(r.Context(), PageIDKey, intPageID)
next.ServeHTTP(w, r.WithContext(ctx))
})
}
(source)
The middleware takes care of some common operations every paginated response has to do. It extracts the next_page query parameter, transforms it into an integer (this might not be necessary depending ont he type of key in your database) and injects it into the context.
Once the /articles?page_id=1 endpoint is hit, we just get the page id from the context and call the database from within the http handler:
func ListArticles(w http.ResponseWriter, r *http.Request) {
pageID := r.Context().Value(m.PageIDKey)
if err := render.Render(w, r, DBClient.GetArticles(pageID.(int))); err != nil {
_ = render.Render(w, r, types.ErrRender(err))
return
}
}
(source)
I like the database logic for pagination the most: We basically get all items of a table, ordered by their primary key, that are greater than the queried ID and limit it to one larger than the page size. That is so we can return a slice with the defined page size as length and use the extra item to insert the next_page_id into the API response. For example if we assume a page size of 10 and have 22 items in a database table with IDs 1-22 and we receive a query with a page id of 10, then we query the database for items 10-20 (including, that means it’s 11 distinct items), package items 10-19 up into the API response and use the 11th item to add the "next_page_id": 20 to the API response. This logic looks as follows:
// GetArticles returns all articles from the database
func (c *Client) GetArticles(pageID int) *types.ArticleList {
articles := &types.ArticleList{}
c.Client.Where("id >= ?", pageID).Order("id").Limit(pageSize + 1).Find(&articles.Items)
if len(articles.Items) == pageSize+1 {
articles.NextPageID = articles.Items[len(articles.Items)-1].ID
articles.Items = articles.Items[:pageSize] // this shortens the slice by 1
}
return articles
}
(source)
For this to work as efficient as intended, it’s important that the database table’s primary key is the id column we are ordering by in the example above. With that the described database query is fairly efficient, as the IDs are already stored in order in a tree and the database doesn’t have to start ordering once the request is received. All the database has to do is find the queried ID (which the database can do via binary search in O(log n)) and then return the next pageSize items.
The API response will look something like this (shortened):
{
"items":[
{"id":1,"name":"Jelly Beans","price":2.99}
{"id":2,"name":"Skittles","price":3.99}
],
"next_page_id": 3
}
Tags: go, golang, api, programming, software development, repo, ultimate guide, pagination
How to add a Read More Button That Doesn't Suck to Your Jekyll Blog
Jekyll is a great piece of software. It has simple, yet powerful features to cheaply run a personal website, including a blog. However, once I had the idea to add the functionality of a ‘read more…’ button, I couldn’t find a satisfying tutorial that would explain how to properly add such a feature. The problem was, that all the tutorials I found had in common that the ‘read more…’ button is just an anchor tag to the location in the text where the button was placed. My issue with that was, that the reader always had to wait for a page to load. And even after that the height on the screen of where they left off is most likely not the same as after the reload, so that they end up searching for where they left off before the reload.
My goal was that the hidden part of the blog post instantaneously shows up without moving the text around on the screen. Continue reading to find out how I did it.
Step 1: Add <!--more--> tag to posts
The <!--more--> in a post is an html comment and won’t show up on your final page, but it will help our .html file to hide the part of your blog post that should only show up once the button is clicked. Place it anywhere in your post to hide the part below it.
Step 2: Split the post in the .html file
Chances are, that in the .html file that you use to render your blog, you have a loop iterating over your posts looking something like this:
<div class="blog">
{% for page in paginator.posts %}
<article class="post" itemscope itemtype="http://schema.org/BlogPosting">
{{ page.content }}
</article>
{% endfor %}
</div>
All we need to do is check for the <!--more--> tag and put the second half into it’s own <div>. The button itself is actually a checkbox that we will style later to make it look nice. But this checkbox will help us with the toggle feature. So let’s go ahead and replace the {{ page.content }} part with the following:
{% if page.content contains '<!--more-->' %}
<div>
{{ page.content | split:'<!--more-->' | first }}
</div>
<input type="checkbox" class="read-more-state" id="{{ page.url }}"/>
<div class="read-more">
{{ page.content | split:'<!--more-->' | last }}
</div>
<label for="{{ page.url }}" class="read-more-trigger"></label>
{% else %}
{{ page.content }}
{% endif %}
Step 3: Let’s add some style
Just add the following to your css and play around with it until you like it:
.read-more {
opacity: 0;
max-height: 0;
font-size: 0;
transition: .25s ease;
display: none;
}
.read-more-state {
display: none;
}
.read-more-state:checked ~ .read-more {
opacity: 1;
font-size: inherit;
max-height: 999em;
display: inherit;
}
.read-more-state ~ .read-more-trigger:before {
content: 'Continue reading...';
}
.read-more-state:checked ~ .read-more-trigger:before {
content: 'Show less...';
}
.read-more-trigger {
cursor: pointer;
padding: 1em .5em;
color: #0085bd;
font-size: .9em;
line-height: 2;
border: 1px solid #0085bd;
border-radius: .25em;
font-weight: 500;
display: grid;
text-align: center;
}
And voilà!!! We have a really nice ‘Continue reading…’ button that changes into a ‘Show less…’ as soon as it’s expanded. You can try it out on most of my posts on my homepage. If you have any question or feedback, feel free to drop my a line on any of my social media. Thanks for reading!
Tags: blog, tutorial, jekyll, how-to
How to write a Go API Part 3: Testing With Dockertest
This is part 3 of 3 blog posts on how to write a Go API. Read the first and second part first to build upon the repository. If you are only interested in testing your API, make sure to download the source code of the second part, as we are incrementally building upon it.
This part is all about testing our Go API. The challenge here is to mock the webserver and the database. Iris comes with it’s own testing package. To test the database, I have found that Dockertest is a pretty good choice, as it is the only possibility to mock the actual setup of the database inside a Docker container. The module spins up a defined Docker container, runs the tests and destroys it again as if nothing happened. So make sure you have Docker installed and the daemon up and running as you are executing the tests.
Let’s get started with the code by creating a new file:
echo "package main" >> main_test.go
For typical Go tests, this would be the file that contains all the unit tests. These are basically functions starting with the word Test.... And we will get to them later, but in our case we have some preliminary steps that are needed for all our unit tests later. And that is setting up the database and starting up the Iris application. That’s what we will do first.
Add the following code into the main_test.go file:
var db *gorm.DB
var app *iris.Application
func TestMain(m *testing.M) {
}
The two variables db and app are both empty pointers to a *gorm.DB and a *iris.Application, which we will fill with life later. The TestMain(m *testing.M) function is automatically executed by Go before the tests run. So this is where we set up the app and the database. Let’s start with the database, since the app needs the database, as described in part two. In the following, we will successively add little code blocks into the TestMain() function and I will show the entire code in the end.
First, we need to create a pool in which we can run the Docker container later:
// Create a new pool for Docker containers
pool, err := dockertest.NewPool("")
if err != nil {
log.Fatalf("Could not connect to Docker: %s", err)
}
In order to run the pool, we need to define an options object with all the parameters for the Docker container we want to run. We basically spin up the same Docker container as in part two, but this time with Go code. I also changed the port, just in case you still have the Postgres Docker container running from part two:
// Pull an image, create a container based on it and set all necessary parameters
opts := dockertest.RunOptions{
Repository: "mdillon/postgis",
Tag: "latest",
Env: []string{"POSTGRES_PASSWORD=mysecretpassword"},
ExposedPorts: []string{"5432"},
PortBindings: map[docker.Port][]docker.PortBinding{
"5432": {
{HostIP: "0.0.0.0", HostPort: "5433"},
},
},
}
// Run the Docker container
resource, err := pool.RunWithOptions(&opts)
if err != nil {
log.Fatalf("Could not start resource: %s", err)
}
Next, we will try and connect to the database just as the actual code in the main.go file would try and connect to the database.
github.com/ory/dockertest package has a build-in Retry() function, that tries to connect to the database in a loop with exponentially growing time intervals in between. Add this code underneath the last:
// Exponential retry to connect to database while it is booting
if err := pool.Retry(func() error {
databaseConnStr := fmt.Sprintf("host=localhost port=5433 user=postgres dbname=postgres password=mysecretpassword sslmode=disable")
db, err = gorm.Open("postgres", databaseConnStr)
if err != nil {
log.Println("Database not ready yet (it is booting up, wait for a few tries)...")
return err
}
// Tests if database is reachable
return db.DB().Ping()
}); err != nil {
log.Fatalf("Could not connect to Docker: %s", err)
}
Note how we fill the db object defined earlier here. So as soon as we successfully leave the Retry() function, we have our database ready and can now populate it with the test data. To structure code a little better, I usually do that in a separate function (in this same file). So just add the following function and variable for samples right next to the TestMain() function:
func initTestDatabase() {
db.AutoMigrate(&model.Order{})
db.Save(&sampleOrders[0])
db.Save(&sampleOrders[1])
}
var sampleOrders = []model.Order{
{
ID: 1,
Description: "An old glove",
Ts: time.Now().Unix() * 1000,
},
{
ID: 2,
Description: "Something you don't need",
Ts: time.Now().Unix() * 1000,
},
}
Back inside the TestMain() function, we can then call the initTestDatabase() function, as well as create the mock Iris app for the tests:
log.Println("Initialize test database...")
initTestDatabase()
log.Println("Create new Iris app...")
app = newApp(db)
Now, right after we have the app and the db ready, we can finally run our actual test cases, which we will define later. At this point we will just call
// Run the actual test cases (functions that start with Test...)
code := m.Run()
Once the test cases have run, we will just remove the Docker container and exit the program:
// Delete the Docker container
if err := pool.Purge(resource); err != nil {
log.Fatalf("Could not purge resource: %s", err)
}
os.Exit(code)
At this point we can now add our actual test cases (functions that start with Test...). To compare the actual result with an expected result, we use the package github.com/stretchr/testify. I have annotated the following code to understand what we are doing:
func TestName(t *testing.T) {
// Request an endpoint of the app
e := httptest.New(t, app, httptest.URL("http://localhost"))
t1 := e.GET("/Bill").Expect().Status(iris.StatusOK)
// Compare the actual result with an expected result
assert.Equal(t, "Hello Bill", t1.Body().Raw())
}
func TestOrders(t *testing.T) {
e := httptest.New(t, app, httptest.URL("http://localhost"))
t1 := e.GET("/orders").Expect().Status(iris.StatusOK)
expected, _ := json.Marshal(sampleOrders)
assert.Equal(t, string(expected), t1.Body().Raw())
}
Now, I don’t assume that any of you have kept track of all the necessary imports we need for all the code above. So here is the import block that we need in the beginning of the test_main.go file:
import (
"encoding/json"
"fmt"
"log"
"my-go-api/model"
"os"
"testing"
"time"
"github.com/jinzhu/gorm"
"github.com/kataras/iris/v12"
"github.com/kataras/iris/v12/httptest"
"github.com/ory/dockertest"
"github.com/ory/dockertest/docker"
"github.com/stretchr/testify/assert"
)
And that’s it 🎉! We can now run the tests with
go test -v
And we will get the following output:
2019/02/17 08:15:06 Database not ready yet (it is booting up, wait for a few tries)...
2019/02/17 08:15:12 Initialize test database...
2019/02/17 08:15:12 Create new Iris app...
=== RUN TestName
--- PASS: TestName (0.00s)
=== RUN TestOrders
--- PASS: TestOrders (0.00s)
PASS
ok my-go-api 17.111s
Yay! The tests are successful 👍🏼
If you missed something, click here to see the code of the entire test_main.go file, or just download the entire source code of the project.
Tags: go, golang, api, programming, software development, repo, go base project, dockertest